Spark实战电影点评系统(二)
华为Mate 50 Pro相机评测:强大影像系统实测 #生活知识# #科技生活# #科技产品评测#
二、通过DataFrame实战电影点评系统
DataFrameAPI是从Spark 1.3开始就有的,它是一种以RDD为基础的分布式无类型数据集,它的出现大幅度降低了普通Spark用户的学习门槛。
DataFrame类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以解析到具体数据的结构信息,从而对DataFrame中的数据源以及对DataFrame的操作进行了非常有效的优化,从而大幅提升了运行效率。
现在我们通过实现几个功能来了解DataFrame的具体用法。先来看第一个功能:通过DataFrame实现某部电影观看者中男性和女性不同年龄分别有多少人。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
println("========================================")
println("功能一:通过DataFrame实现某部电影观看者中男性和女性不同年龄人数")
val schemaForUsers = StructType(
"UserID::Gender::Age::OccupationID::Zip-code".split("::")
.map(column => StructField(column,StringType,true))
)
val usersRDDRows = usersRDD.map(_.split("::")).map(
line => Row(line(0).trim(),line(1).trim(),line(2).trim(),line(3).trim(),line(4).trim())
)
val usersDataFrame = spark.createDataFrame(usersRDDRows, schemaForUsers)
val schemaforratings = StructType(
"UserID::MovieID".split("::")
.map(column => StructField(column,StringType,true)))
.add("Rating",DoubleType,true)
.add("Timestamp",StringType,true)
val ratingsRDDRows = ratingsRDD.map(_.split("::")).map(
line => Row(line(0).trim(),line(1).trim(),line(2).trim().toDouble,line(3).trim())
)
val ratingsDataFrame = spark.createDataFrame(ratingsRDDRows, schemaforratings)
val schemaformovies = StructType(
"MovieID::Title::Genres".split("::")
.map(column => StructField(column,StringType,true))
)
val moviesRDDRows = moviesRDD.map(_.split("::")).map(line => Row(line(0).trim(),line(1).trim(),line(2).trim()))
val moviesDataFrame = spark.createDataFrame(moviesRDDRows, schemaformovies)
ratingsDataFrame.filter(s"MovieID==1193")
.join(usersDataFrame,"UserID")
.select("Gender", "Age")
.groupBy("Gender", "Age")
.count().show(10)
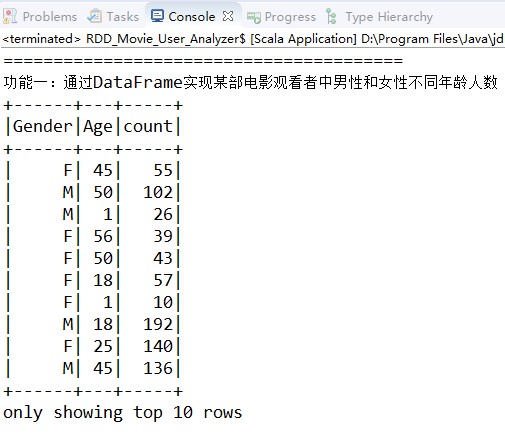
上面案例中的代码无论是从思路上,还是从结构上都和SQL语句十分类似,下面通过写SQL语句的方式来实现上面的案例。
1
2
3
4
5
6
7
8
println("========================================")
println("功能二:用LocalTempView实现某部电影观看者中不同性别不同年龄分别有多少人")
ratingsDataFrame.createTempView("ratings")
usersDataFrame.createTempView("users")
val sql_local = "SELECT Gender,Age,count(*) from users u join ratings as r on u.UserID=r.UserID where MovieID=1193 group by Gender,Age"
spark.sql(sql_local).show(10)

这篇博文主要来自《Spark大数据商业实战三部曲》这本书里面的第一章,内容有删减,还有本书的一些代码的实验结果。随书附赠的代码库链接为:https://github.com/duanzhihua/code-of-spark-big-data-business-trilogy
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。
网址:Spark实战电影点评系统(二) https://klqsh.com/news/view/195048
相关内容
Spark实战电影点评系统(一)电影点评系统分析报告.pptx
电影推荐与点评系统的设计与实现
电影评论发布及其评价系统设计与实现
电影评论网站系统设计与实现——开题报告
楚信大屏幕触摸屏电视图文点评系统
电影影评观后感
系统界面实现及介绍
战场上冲锋最快的士兵,居然去干这件事!战争电影 电影解说 二战电影战争片 推荐电影
徐峥《囧妈》电影评价精彩点评
随便看看
最新乐趣
- 吃货之间不需要解释,闻臭香才是真爱
- 师父这一次的“欺骗”太痛了,痛得多希望只是一场梦
- 薛凯琪 微博VC计划
- 巩俐出席活动气质出众状态绝佳
- 玄彬 恋爱 微博VC计划
- 小雨版“小鸡”舞来也
- 阿玛尼芍药
- 太好了!冉冉在最后一刻坚持住了底线扭头就走
- 玄彬 娱乐达人团
- 啊这个小真就是掌握平地摔的神 冉好!地坏! 她好可爱
热点乐趣
- 86123
- 62301
- 60376
- 52879
- 34065
- 31072
- 29496
- 22203
- 18151
- 16609

